
- Power View и OLAP в Excel
- Дополнительные ресурсы
- Сводные таблицы Excel
- Создаем OLAP куб. Часть 1
- Немного теории.
- Каким же должен быть Data Warehouse?
- Звезда.
- А теперь снежинка.
- HabraDW.
- Итоговая схема нашей звезды будет такой.
- Анализ данных кубов OLAP в Service Manager с помощью Excel
- Просмотр и анализ куба данных Service Manager OLAP с Excel
- Просмотр и анализ куба OLAP в приложении Excel
- использование срезов Excel для просмотра данных Service Manager куба OLAP
Power View и OLAP в Excel
Важно: В Excel для Microsoft 365 Excel 2021 Power View удаляется 12 октября 2021 г. В качестве альтернативы вы можете использовать интерактивный визуальный эффект, предоставляемый Power BI Desktop,который можно скачать бесплатно. Вы также можете легко импортировать книги Excel в Power BI Desktop.
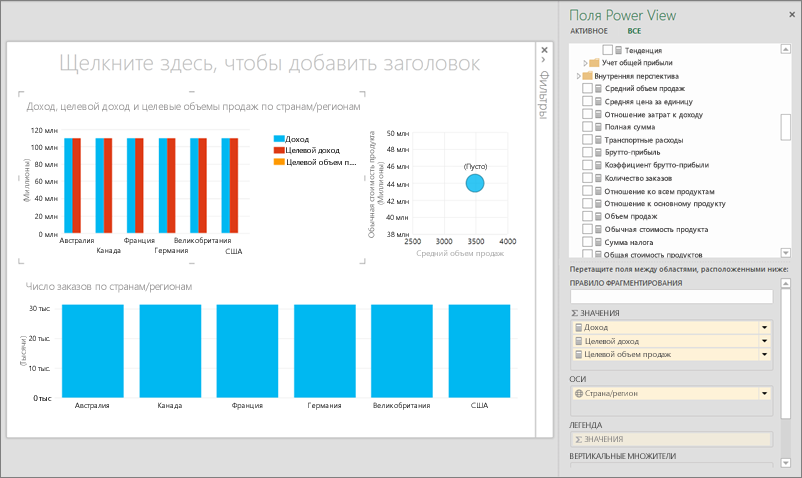
В Excel вы можете подключаться к кубам OLAP (часто называемым многомерными кубами) и создавать интересные и привлекательные страницы отчетов с помощью Power View.
Чтобы подключиться к источнику многомерных данных, на ленте выберите Данные > Получение внешних данных > Из других источников > Из служб аналитики.
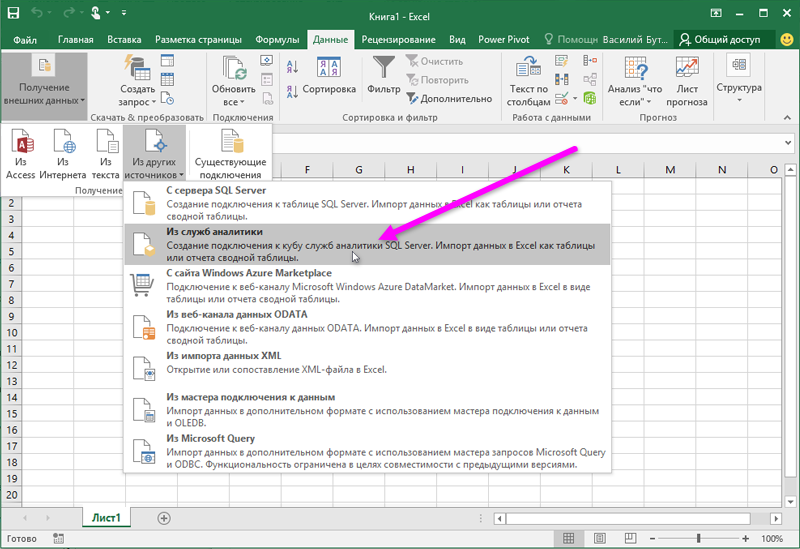
В мастере подключения к данным введите имя сервера, на котором размещен куб, а затем выберите и укажите нужные учетные данные.
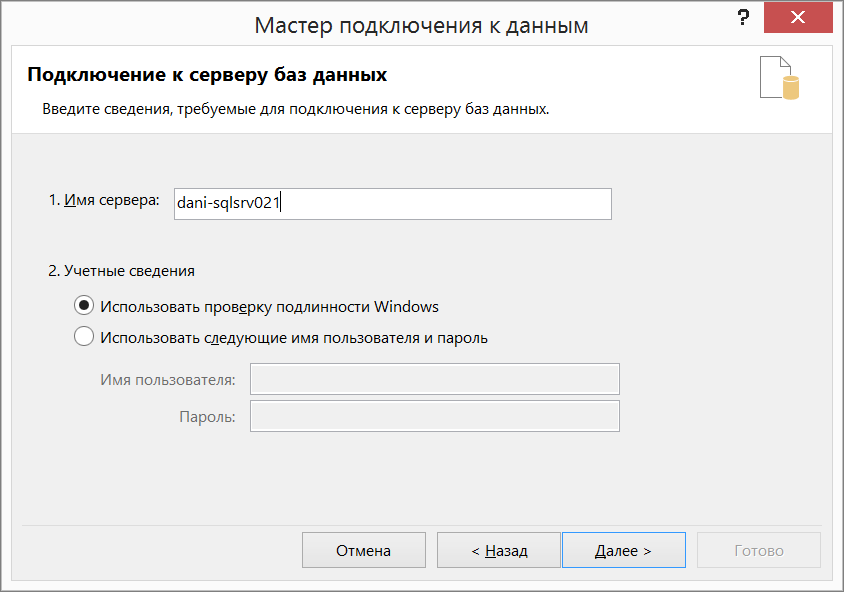
Появится диалоговое окно, в котором перечислены базы данных, таблицы и кубы, доступные на сервере.
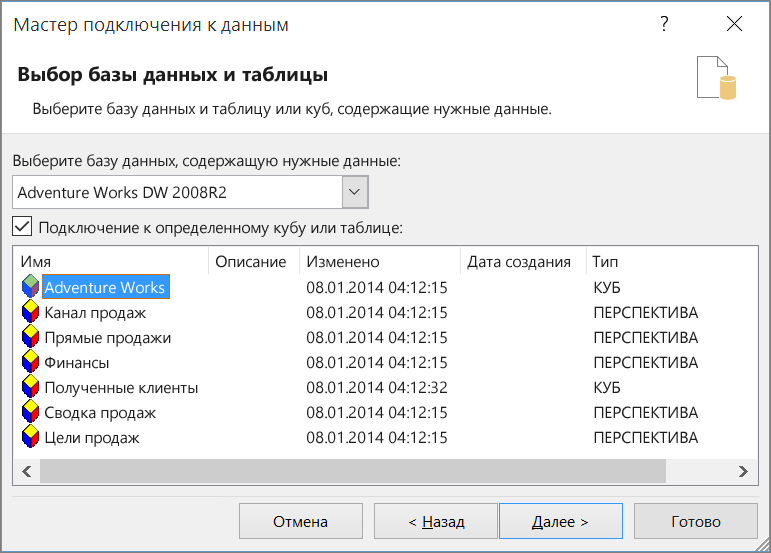
Выбрав нужный куб и на выбрав далее ,вы можете выбрать, где будут просматриваться подключенные данные в книге. В этом случае вы хотите создать отчет Power View, поэтому нажать кнопку рядом с кнопкой Отчет Power View.
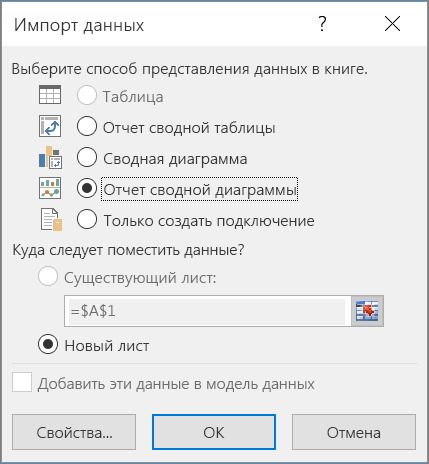
В области Поля Power View можно просмотреть доступные поля куба.
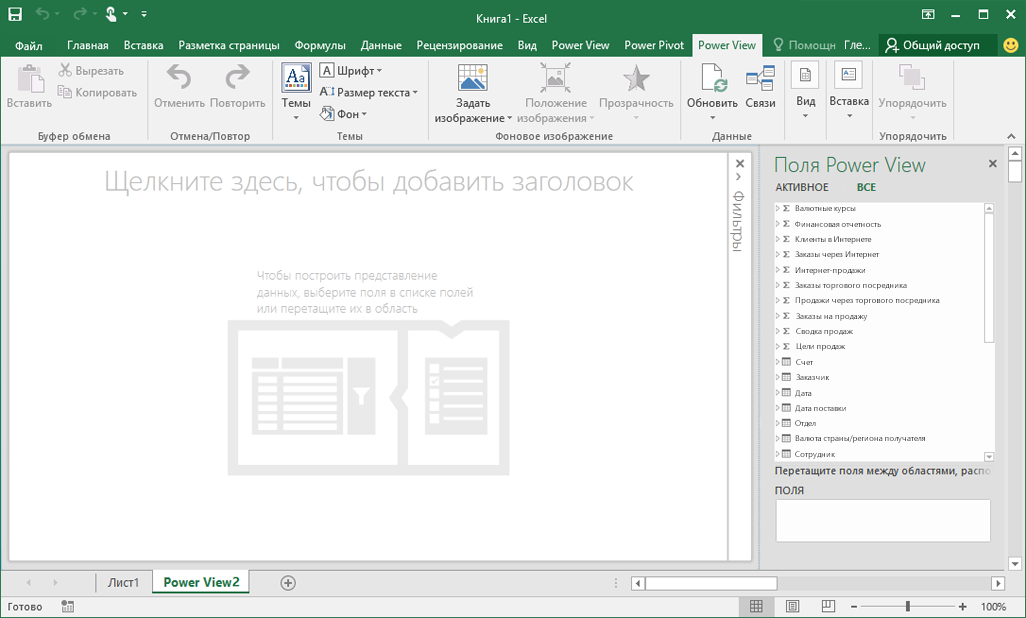
Теперь вы можете использовать данные из куба для создания убедительных отчетов. Данные могут быть различных типов, включая следующие:
Группы мер — это коллекция мер, существующих в кубе.
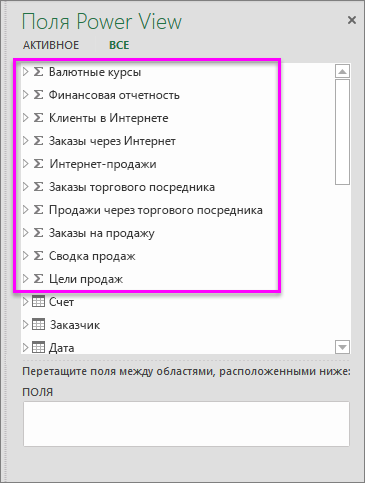
Меры и ключевые показатели эффективности в пределах группы мер — вы также можете использовать отдельные меры и ключевые показатели эффективности из группы мер. Разверните группу мер, чтобы просмотреть доступные в ней элементы, как показано на снимке экрана.
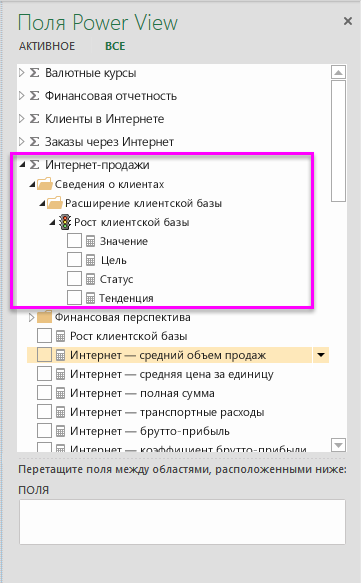
Измерения, атрибуты и иерархии — вы также можете использовать прочие поля куба, как в любом другом отчете.
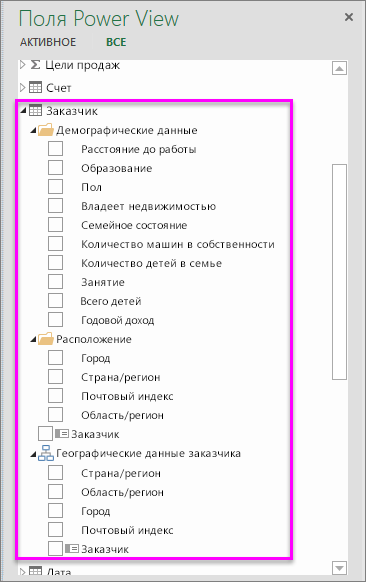
С помощью таких полей вы можете создавать интересные интерактивные отчеты на основе Power View и кубов OLAP.
Дополнительные ресурсы
Дополнительные сведения о Power View, OLAP и службах Analysis Services см. в следующих статьях:
Сводные таблицы Excel
В стандартной сводной таблице исходные данные хранятся на локальном жестком диске. Таким образом, вы всегда можете управлять ими и переорганизовывать их, даже не имея доступа к сети. Но это ни в коей мере не касается сводных таблиц OLAP. В сводных таблицах OLAP кеш никогда не хранится на локальном жестком диске. Поэтому сразу же после отключения от локальной сети ваша сводная таблица утратит работоспособность. Вы не сможете переместить в ней ни одного поля.
Если вам все же необходимо анализировать OLAP-данные после отключения от сети, создайте автономный куб данных. Автономный куб данных — это отдельный файл, который представляет собой кеш сводной таблицы и хранит OLAP-данные, просматриваемые после отключения от локальной сети. OLAP-данные, скопированные в сводную таблицу, можно распечатать, на сайте http://everest.ua подробно об этом рассказано.
Чтобы создать автономный куб данных, сначала создайте сводную таблицу OLAP. Поместите курсор в пределах сводной таблицы и щелкните на кнопке Средства OLAP (OLAP Tools) контекстной вкладки Параметры (Tools), входящей в группу контекстных вкладок Работа со сводными таблицами (PivotTable Tools). Выберите команду Автономный режим OLAP (Offline OLAP) (рис. 9.8).

Рис. 9.8. Создание автономного куба данных
На экране появится диалоговое окно настроек автономного куба данных OLAP. Щелкните в нем на кнопке Создать автономный файл данных (Create Offline Data File). Вы запустили мастер создания файла куба данных. Щелкните на кнопке Далее (Next), чтобы продолжить процедуру.
Cначала необходимо указать размерности и уровни, которые будут включаться в куб данных. В диалоговом окне необходимо выбрать данные, которые будут импортироваться из базы данных OLAP. Идея состоит в том, чтобы указать только те размерности, которые понадобятся после отключения компьютера от локальной сети. Чем больше размерностей укажете, тем больший размер будет иметь автономный куб данных.
Щелкните на кнопке Далее для перехода к следующему диалоговому окну мастера. В нем вы получаете возможность указать члены или элементы данных, которые не будут включаться в куб. В частности, вам не потребуется мера Internet Sales-Extended Amount, поэтому флажок для нее будет сброшен в списке. Сброшенный флажок указывает на то, что указанный элемент не будет импортироваться и занимать лишнее место на локальном жестком диске.
На последнем этапе укажите расположение и имя куба данных. В нашем случае файл куба будет назван MyOfflineCube.cub и будет располагаться в папке Work.
Файлы кубов данных имеют расширение .cub
Спустя некоторое время Excel сохранит автономный куб данных в указанной папке. Чтобы протестировать его, дважды щелкните на файле, что приведет к автоматической генерации рабочей книги Excel, которая содержит сводную таблицу, связанную с выбранным кубом данных. После создания вы можете распространить автономный куб данных среди всех заинтересованных пользователей, которые работают в режиме отключенной локальной сети.
После подключения к локальной сети можно открыть автономный файл куба данных и обновить его, а также соответствующую таблицу данных. Главный принцип гласит, что автономный куб данных применяется только для работы при отключенной локальной сети, но он в обязательном порядке обновляется после восстановления соединения. Попытка обновления автономного куба данных после разрыва соединения приведет к сбою.
Создаем OLAP куб. Часть 1

Продолжая тематику Многомерные кубы, OLAP и MDX и olap для маленькой компании, традиционно, предлагаю начать с простенького «Hello World» куба, который будет анализировать процессы и тенденции голосований на Хабре.
Итак, давайте попробуем создать свою первую OLAP систему.
Но, прежде чем, потирая руки, запускать Business Intelligence Studio, предлагаю вначале создать хранилище данных хабра-голосов, так называемый Data Warehouse.
Зачем? Причин в этом несколько:
- сама суть Data Warehouse-а хранить «очищенные» данные, готовые для анализа, поэтому даже его изначальная структура может сильно отличаться от структуры нашей хабра-OLTP базы данных
- в HabraDW (так мы его назовем) мы вынесем только ту информацию, которая нам нужна будет для анализа, ничего лишнего
- к Data Warehouse не накладываются требования нормализации. Даже наоборот, денормализировав некоторые данные можно добиться более понятной схемы для построения куба, а также скорости загрузки данных в куб
Немного теории.
По сути, Data Warehouse может быть:
- чисто виртуальный (например, определенным как множество SELECT-ов или даже вызовов сложных хранимых процедур, которые каким-то образом определят входные данные для куба)
- вполне реальным, то есть существовать физически на каком-то сервере (или серверах)
В последнем случае, вы, скорее всего, захотите имплементировать ETL процессы (используя Integration Services или что-то еще), но это уже повод для другой, не менее интересной, статьи.
Каким же должен быть Data Warehouse?
Все очень просто – ваш Data Warehouse должен иметь структуру формы звездочки (star model) или снежинки (snowflake model) и состоять из фактов (facts) и измерений (dimensions).
Факты – это фактические записи (records) о каком-то процессе, который мы хотим анализировать, например, процесс голосования на Хабра, или процесс изменения цены товара на бирже. Очень часто факты содержат какие-нибудь числовые данные, например, фактическое значение голоса или цены.
Измерения – это определяющие атрибуты фактов, и обычно отвечают на всякие вопросы: когда произошел факт, над чем или с чем именно, кто был объектом или субъектом и т.п. В основном, измерения имеют более описательный (то есть текстовый) характер, например, имя пользователя или название месяца, так как конечному пользователю будет намного легче воспринимать результаты описанные текстом (например, название месяца), нежели цифрами (номер месяца в году).
Определив где у нас факты, а где измерения — очень просто построить модель звезды.
Звезда.
В центре указываем нашу таблицу фактов, а лучами выводим измерения.
А теперь снежинка.
Снежинка — это та же звезда, только измерения могут зависеть от измерений следующего уровня, а те в свою очередь могут включать еще уровни.
Каждая из этих моделей имеет свои достоинства и недостатки и собственно выбор модели должен базироваться на требованиях к дизайну куба, скорости загрузки данных, дискового пространства и т.д.
Естественно, конечные Data Warehouse обычно намного сложнее и состоят из нескольких звезд или снежинок, которые могут совместно использовать общие измерения.
HabraDW.
Перейдем к собственно разработке нашего Data Warehouse-а.
Наша цель – анализ тенденций голосования на Хабре, нахождение закономерностей и трендов.
Основные тенденции, которые мы хотим определить:
- в какое время года/месяца/недели голосуют лучше/хуже/чаще
- как голосуют по пятницам и понедельникам (например)
- как влияет на результат голосования наличие в посте слов Microsoft, или Карма
- средняя активность пользователей, «пики» голосования
- и т.п.
Для наглядности, наша первая модель будет абсолютно простой – включим только то, что относится к голосованию и исключим все лишнее, включая время регистрации пользователей и факт того, кто именно запостил статью, а также время голосования (только дата) и остальные атрибуты (все эти данные можно будет включить в следующих статьях и попробовать анализировать более сложные вещи).
В итоге, имеем следующие таблицы:
- Таблица фактов FactHabravote – определяет кто, когда, за что и как именно проголосовал. Значение Vote в нашем случае будет +- 1, но тип поля позволяет расширить дельту голосами, например, +- 10
- Измерение времени DimTime – определяет нужные для анализа атрибуты времени (значения и названия)
- Измерение пользователей DimUser – определяет пользователей Хабра, пока только никнейм
- Измерение постов DimPost – определяет посты, в нашем случае содержит заголовок и булевые поля, определяющие содержит ли пост слова Microsoft и Карма.
Итоговая схема нашей звезды будет такой.
А здесь исходный SQL скрипт, который создает и наполняет (пока что только случайными данными) наше хранилище.
Ну вот, теперь все готово, чтобы загрузить данные в куб.
До встречи в следующей статье.
Анализ данных кубов OLAP в Service Manager с помощью Excel
Эта версия Service Manager достигла конца поддержки, рекомендуется выполнить обновление до Service Manager 2019.
Service Manager включает предопределенные кубы данных Microsoft OLAP, которые подключаются к хранилищу данных для получения данных, чтобы можно было манипулировать ими с помощью Microsoft Excel в табличном виде. При открытии куб данных представлен в виде листа, содержащего пустой отчет сводной таблицы. Сведения, указывающие источник данных OLAP, встроены в лист. При открытии отчета или обновлении подключения к данным, приложение Excel использует службы SQL Server Analysis Services (SSAS), чтобы подключиться к хранилищу данных для получения ключевых показателей эффективности (KPI) и других данных. После открытия текущий лист содержит моментальный снимок или подмножество данных из хранилища данных. При сохранении листа сведения о подключении к источнику данных, показатели KPI, а также любые сделанные вами изменения сохраняются вместе с ним. Если лист сохраняется в библиотеке анализа, его можно открыть позже без использования консоли Service Manager.
Ключевые показатели эффективности, включенные в Service Manager Кубы данных, являются предопределенными, специальными вычисляемыми мерами, определенными на сервере, которые позволяют отслеживанию ключевых показателей эффективности, таких как состояние (текущее значение соответствует определенному числу?). и тренд (как меняется значение с течением времени?). При отображении этих показателей KPI в сводной таблице сервер может отправлять соответствующие значки, представленные в стиле нового набора значков Excel, для отображения уровней состояния, находящихся выше или ниже определенного порога (например, значком стоп-сигнала), а также тренда значения — рост или убывание (к примеру, с помощью значков со стрелками).
Сводные таблицы могут помочь быстро и легко создавать полезные отчеты. Сводные таблицы, отображаемые в Service Manager Data Cubes, включают множество стандартных категорий ключевых показателей эффективности, называемых группами мер или измерениями. Эти группы предоставляют обзор данных с высочайшего уровня классификации и позволяют облегчить фокусировку анализа. Большинство групп мер имеют множество дополнительных уровней подкатегорий и индивидуальных полей. Все категории, подкатегории и поля содержатся в списке полей сводной таблицы. Чтобы создать простой отчет, выполните следующие действия:
- В списке полей сводной таблицы выберите категорию и добавьте ее в виде строки.
- Выберите вторую категорию и добавьте ее в виде столбца.
- Выберите категорию или подкатегорию для добавления значений.
После создания отчета можно добавить любой дополнительный уровень сложности, в том числе сортировку, фильтрацию, форматирование, вычисления и диаграммы. Продолжая анализ, вы также можете входить в категории и покидать их.
демонстрация создания отчета и манипулирования данными в Excel помощью данных из куба данных OLAP в сводной таблице см. в разделе детализация данных сводной таблицы.
Просмотр и анализ куба данных Service Manager OLAP с Excel
для просмотра и анализа куба данных Microsoft OLAP из System Center-Service Manager с Microsoft Excel можно использовать следующую процедуру. Можно также сохранить книги в библиотеке аналитики. С помощью списка полей PivotTable можно перетаскивать поля из куба в книгу. для использования следующей процедуры на компьютере с консолью Service Manager необходимо установить Microsoft Excel 2007 или более поздней версии.
Если анализ куба с помощью Excel выполняется впервые, загрузка может занять несколько минут.
Просмотр и анализ куба OLAP в приложении Excel
- В консоли Service Manager щелкните хранилище данных, разверните узел хранилище данных , а затем щелкните Кубы.
- В области Кубы выберите имя куба, а затем в области Задачивыберите пункт Анализировать куб в Excel. Например, выберите значение SystemCenterWorkItemsCube , чтобы анализировать данный куб.
- Когда в Excel откроется лист, в него можно перетащить поля из списка полей сводной таблицы и создать срезы и диаграммы.
- Например, чтобы увидеть общее количество в данный момент открытых инцидентов, разверните группу IncidentDimGroupи выберите пункт Открытые инциденты.
- Можно добавить дополнительные поля, чтобы выполнить более сложный анализ. К примеру, можно добавить компьютеры из измерения ComputerDim , выбрав поле DisplayName , чтобы увидеть количество инцидентов, затрагивающих отдельные компьютеры.
- При желании вы можете сохранить рабочую книгу в общую папку или на другой общий ресурс (например, в библиотеку анализа). Дополнительные сведения о библиотеке анализа см. в разделе Использование библиотеки анализа.
использование срезов Excel для просмотра данных Service Manager куба OLAP
Наиболее полезные данные отчетов, доступные в Service Manager, представлены в виде кубов данных. Одним из способов просматривать данные кубов и манипулировать ими являются сводные таблицы Microsoft Excel. Срезы в Excel можно использовать для фильтрации данных сводной таблицы.
Срезы — это простые в использовании компоненты фильтрации с набором кнопок, позволяющих быстро фильтровать данные в отчете сводной таблицы без необходимости открывать выпадающие списки для обнаружения подлежащих фильтрации элементов.
При использовании обычного фильтра отчетов сводной таблицы для фильтрации по нескольким элементам, фильтр отображает только то, что фильтруются несколько элементов — для того, чтобы узнать более точные сведения о фильтрации, потребуется открыть раскрывающийся список. Однако срез сразу показывает примененный фильтр и предоставляет сведения, позволяющие с легкостью понять данные, отображенные в отфильтрованном отчете сводной таблицы.
дополнительные сведения о Excel срезах см. в разделе использование срезов для фильтрации данных сводной таблицы на Microsoft Office веб-сайте.