
- Power View и OLAP в Excel
- Дополнительные ресурсы
- Анализ данных кубов OLAP в Service Manager с помощью Excel
- Просмотр и анализ куба данных Service Manager OLAP с Excel
- Просмотр и анализ куба OLAP в приложении Excel
- использование срезов Excel для просмотра данных Service Manager куба OLAP
- Общие сведения о кубах OLAP в Service Manager для расширенной аналитики
- О Service Manager кубах OLAP
- Service Manager Кубы OLAP
- Источник данных
- Представление источника данных
- Кубы OLAP
- Измерения
- Группа мер
- Детализация
- Детализация
- Ключевой показатель эффективности
- Разделы
- Агрегации
- Секционирование Куба Service Manager
- Развертывание куба OLAP Service Manager
- Обработка Service Manager куба OLAP
- Обработка измерений.
- Обработка разделов.
- Ведение кубов Service Manager OLAP
- Периодическая повторная обработка Analysis Services измерений
- Требования к памяти
Power View и OLAP в Excel
Важно: В Excel для Microsoft 365 Excel 2021 Power View удаляется 12 октября 2021 г. В качестве альтернативы вы можете использовать интерактивный визуальный эффект, предоставляемый Power BI Desktop,который можно скачать бесплатно. Вы также можете легко импортировать книги Excel в Power BI Desktop.
В Excel вы можете подключаться к кубам OLAP (часто называемым многомерными кубами) и создавать интересные и привлекательные страницы отчетов с помощью Power View.
Чтобы подключиться к источнику многомерных данных, на ленте выберите Данные > Получение внешних данных > Из других источников > Из служб аналитики.
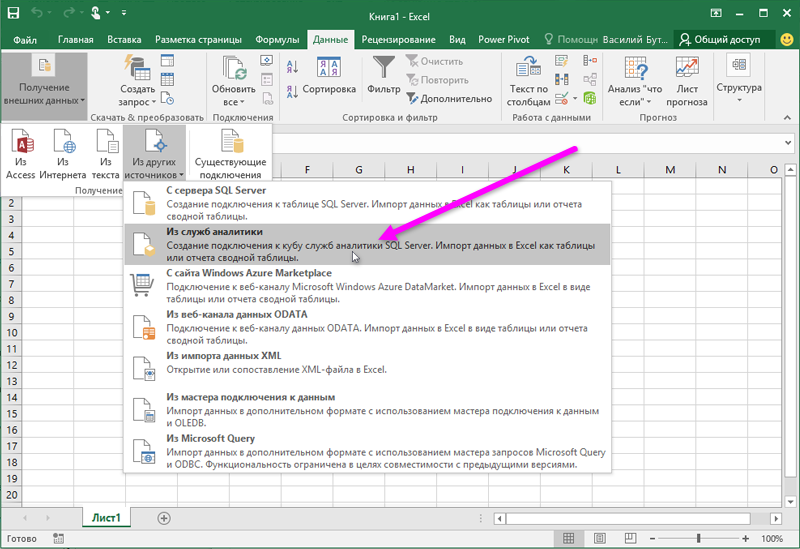
В мастере подключения к данным введите имя сервера, на котором размещен куб, а затем выберите и укажите нужные учетные данные.
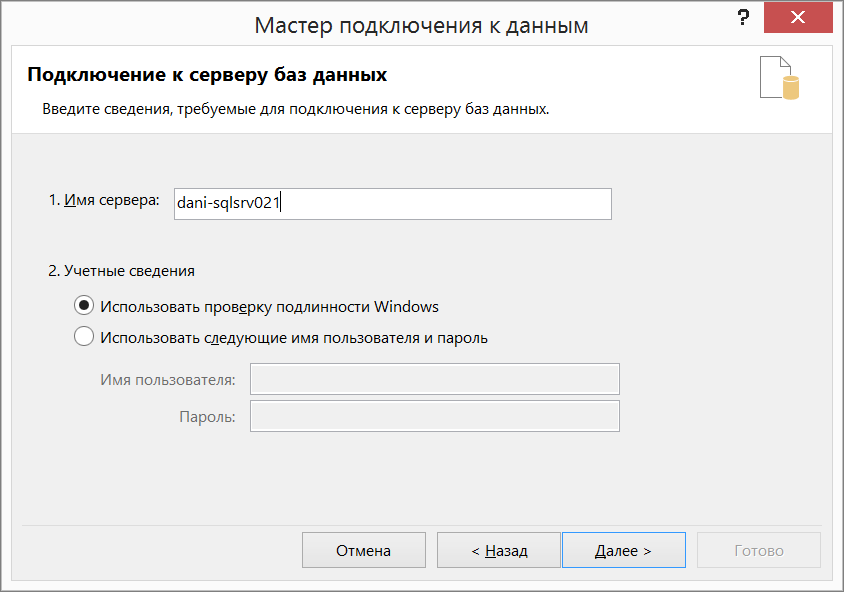
Появится диалоговое окно, в котором перечислены базы данных, таблицы и кубы, доступные на сервере.
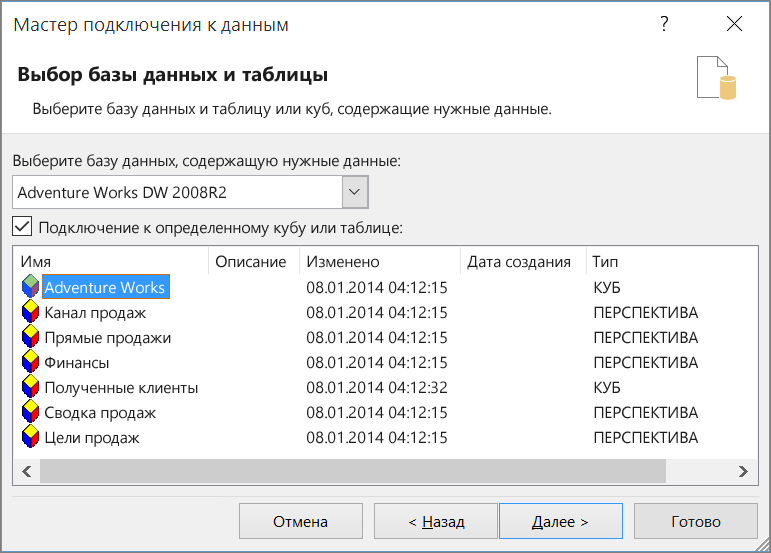
Выбрав нужный куб и на выбрав далее ,вы можете выбрать, где будут просматриваться подключенные данные в книге. В этом случае вы хотите создать отчет Power View, поэтому нажать кнопку рядом с кнопкой Отчет Power View.
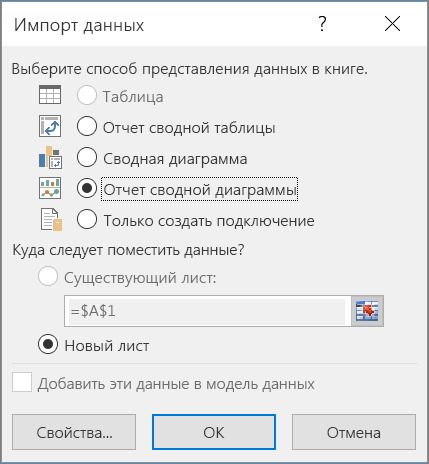
В области Поля Power View можно просмотреть доступные поля куба.
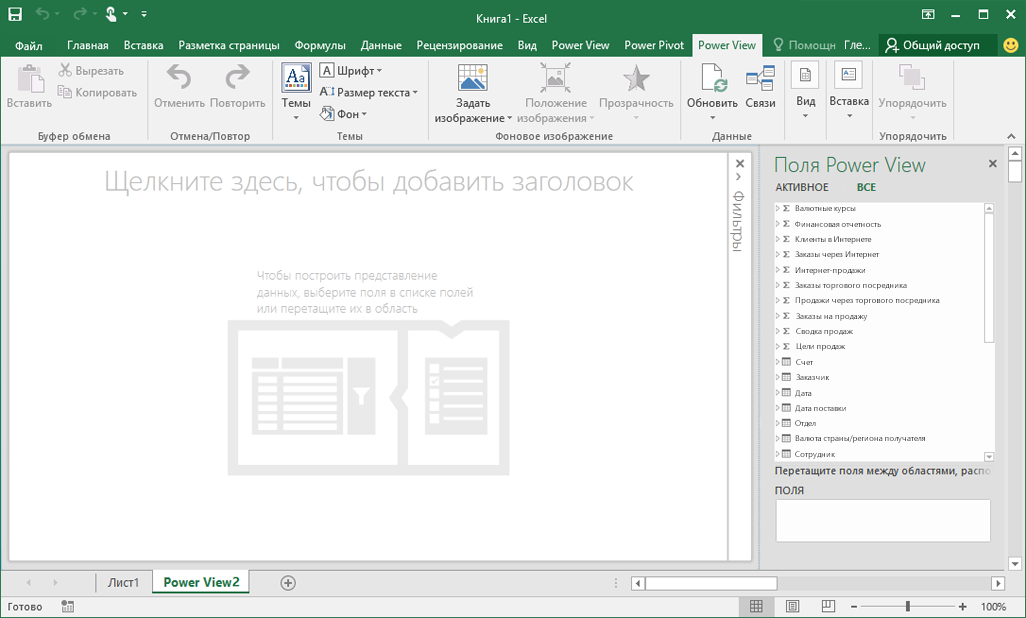
Теперь вы можете использовать данные из куба для создания убедительных отчетов. Данные могут быть различных типов, включая следующие:
Группы мер — это коллекция мер, существующих в кубе.
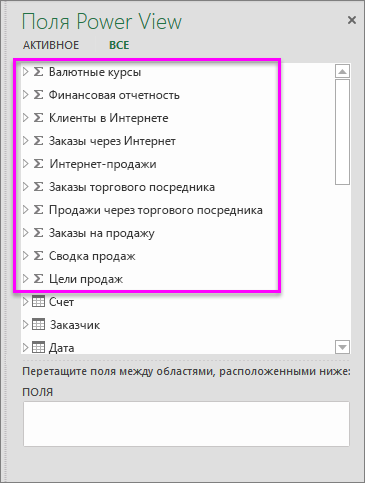
Меры и ключевые показатели эффективности в пределах группы мер — вы также можете использовать отдельные меры и ключевые показатели эффективности из группы мер. Разверните группу мер, чтобы просмотреть доступные в ней элементы, как показано на снимке экрана.
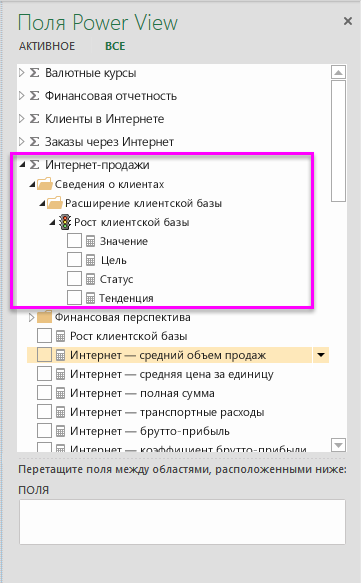
Измерения, атрибуты и иерархии — вы также можете использовать прочие поля куба, как в любом другом отчете.
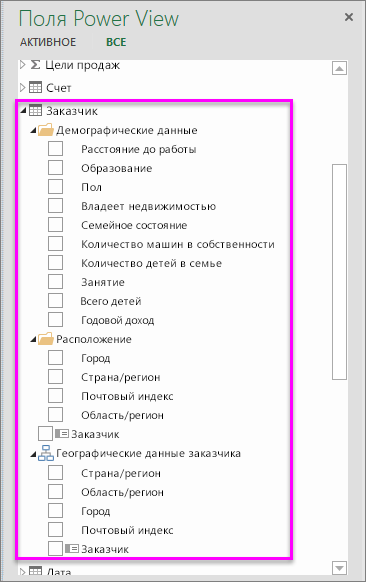
С помощью таких полей вы можете создавать интересные интерактивные отчеты на основе Power View и кубов OLAP.
Дополнительные ресурсы
Дополнительные сведения о Power View, OLAP и службах Analysis Services см. в следующих статьях:
Анализ данных кубов OLAP в Service Manager с помощью Excel
Эта версия Service Manager достигла конца поддержки, рекомендуется выполнить обновление до Service Manager 2019.
Service Manager включает предопределенные кубы данных Microsoft OLAP, которые подключаются к хранилищу данных для получения данных, чтобы можно было манипулировать ими с помощью Microsoft Excel в табличном виде. При открытии куб данных представлен в виде листа, содержащего пустой отчет сводной таблицы. Сведения, указывающие источник данных OLAP, встроены в лист. При открытии отчета или обновлении подключения к данным, приложение Excel использует службы SQL Server Analysis Services (SSAS), чтобы подключиться к хранилищу данных для получения ключевых показателей эффективности (KPI) и других данных. После открытия текущий лист содержит моментальный снимок или подмножество данных из хранилища данных. При сохранении листа сведения о подключении к источнику данных, показатели KPI, а также любые сделанные вами изменения сохраняются вместе с ним. Если лист сохраняется в библиотеке анализа, его можно открыть позже без использования консоли Service Manager.
Ключевые показатели эффективности, включенные в Service Manager Кубы данных, являются предопределенными, специальными вычисляемыми мерами, определенными на сервере, которые позволяют отслеживанию ключевых показателей эффективности, таких как состояние (текущее значение соответствует определенному числу?). и тренд (как меняется значение с течением времени?). При отображении этих показателей KPI в сводной таблице сервер может отправлять соответствующие значки, представленные в стиле нового набора значков Excel, для отображения уровней состояния, находящихся выше или ниже определенного порога (например, значком стоп-сигнала), а также тренда значения — рост или убывание (к примеру, с помощью значков со стрелками).
Сводные таблицы могут помочь быстро и легко создавать полезные отчеты. Сводные таблицы, отображаемые в Service Manager Data Cubes, включают множество стандартных категорий ключевых показателей эффективности, называемых группами мер или измерениями. Эти группы предоставляют обзор данных с высочайшего уровня классификации и позволяют облегчить фокусировку анализа. Большинство групп мер имеют множество дополнительных уровней подкатегорий и индивидуальных полей. Все категории, подкатегории и поля содержатся в списке полей сводной таблицы. Чтобы создать простой отчет, выполните следующие действия:
- В списке полей сводной таблицы выберите категорию и добавьте ее в виде строки.
- Выберите вторую категорию и добавьте ее в виде столбца.
- Выберите категорию или подкатегорию для добавления значений.
После создания отчета можно добавить любой дополнительный уровень сложности, в том числе сортировку, фильтрацию, форматирование, вычисления и диаграммы. Продолжая анализ, вы также можете входить в категории и покидать их.
демонстрация создания отчета и манипулирования данными в Excel помощью данных из куба данных OLAP в сводной таблице см. в разделе детализация данных сводной таблицы.
Просмотр и анализ куба данных Service Manager OLAP с Excel
для просмотра и анализа куба данных Microsoft OLAP из System Center-Service Manager с Microsoft Excel можно использовать следующую процедуру. Можно также сохранить книги в библиотеке аналитики. С помощью списка полей PivotTable можно перетаскивать поля из куба в книгу. для использования следующей процедуры на компьютере с консолью Service Manager необходимо установить Microsoft Excel 2007 или более поздней версии.
Если анализ куба с помощью Excel выполняется впервые, загрузка может занять несколько минут.
Просмотр и анализ куба OLAP в приложении Excel
- В консоли Service Manager щелкните хранилище данных, разверните узел хранилище данных , а затем щелкните Кубы.
- В области Кубы выберите имя куба, а затем в области Задачивыберите пункт Анализировать куб в Excel. Например, выберите значение SystemCenterWorkItemsCube , чтобы анализировать данный куб.
- Когда в Excel откроется лист, в него можно перетащить поля из списка полей сводной таблицы и создать срезы и диаграммы.
- Например, чтобы увидеть общее количество в данный момент открытых инцидентов, разверните группу IncidentDimGroupи выберите пункт Открытые инциденты.
- Можно добавить дополнительные поля, чтобы выполнить более сложный анализ. К примеру, можно добавить компьютеры из измерения ComputerDim , выбрав поле DisplayName , чтобы увидеть количество инцидентов, затрагивающих отдельные компьютеры.
- При желании вы можете сохранить рабочую книгу в общую папку или на другой общий ресурс (например, в библиотеку анализа). Дополнительные сведения о библиотеке анализа см. в разделе Использование библиотеки анализа.
использование срезов Excel для просмотра данных Service Manager куба OLAP
Наиболее полезные данные отчетов, доступные в Service Manager, представлены в виде кубов данных. Одним из способов просматривать данные кубов и манипулировать ими являются сводные таблицы Microsoft Excel. Срезы в Excel можно использовать для фильтрации данных сводной таблицы.
Срезы — это простые в использовании компоненты фильтрации с набором кнопок, позволяющих быстро фильтровать данные в отчете сводной таблицы без необходимости открывать выпадающие списки для обнаружения подлежащих фильтрации элементов.
При использовании обычного фильтра отчетов сводной таблицы для фильтрации по нескольким элементам, фильтр отображает только то, что фильтруются несколько элементов — для того, чтобы узнать более точные сведения о фильтрации, потребуется открыть раскрывающийся список. Однако срез сразу показывает примененный фильтр и предоставляет сведения, позволяющие с легкостью понять данные, отображенные в отфильтрованном отчете сводной таблицы.
дополнительные сведения о Excel срезах см. в разделе использование срезов для фильтрации данных сводной таблицы на Microsoft Office веб-сайте.
Общие сведения о кубах OLAP в Service Manager для расширенной аналитики
Эта версия Service Manager достигла конца поддержки, рекомендуется выполнить обновление до Service Manager 2019.
В Service Manager данные, которые находятся в хранилище данных, можно консолидировать из различных источников. Он представлен в Service Manager с помощью стандартных и настроенных кубов данных Microsoft OLAP. вкратце, расширенная аналитика в Service Manager состоит из публикации, просмотра и манипулирования данными куба, как правило, в Microsoft Excel или в Microsoft SharePoint. Excel в основном используется для просмотра и манипулирования данными. SharePoint в основном используется как средство публикации данных куба и открытия общего доступа к ним.
Service Manager включает хранилище данных на уровне System Center. Таким образом, данные из Operations Manager, Configuration Manager и Service Manager можно консолидировать в хранилище данных, где можно легко использовать несколько представлений данных для получения любых нужных сведений. Кроме того, предусмотрен интерфейс, позволяющий поместить в хранилище данные из собственных пользовательских источников, таких как приложения SAP или приложения отдела кадров от сторонних разработчиков. Подобная консолидация создает общую модель данных и дает возможность выполнять обогащенный анализ, что позволяет вашему ИТ-отделу построить хранилище данных, способное обеспечить все его нужды в сфере производства отчетов и бизнес-аналитики.
Помещение данных в общую модель позволяет манипулировать информацией и создавать общие определения и таксономию для всего предприятия. Это достигается путем развертывания кубов OLAP и просмотра имеющейся в них информации с помощью стандартных средств, таких как Excel и SharePoint. Такой подход позволяет пользователям использовать уже имеющиеся у них навыки. Вы контролируете определение своей бизнес-логики в централизованном режиме. К примеру, вы можете определить ключевые показатели эффективности, такие как пороги допустимого времени устранения инцидента и указать, какие значения будут расцениваться как «зеленый», «желтый» и «красный» пороги. Данную настройку можно выполнять в централизованном режиме, позволяя пользователям с легкостью использовать данные и наблюдать общее определение в своих отчетах Excel и панелях мониторинга SharePoint.
О Service Manager кубах OLAP
Кубы OLAP — это функция в Service Manager, которая использует существующую инфраструктуру хранилища данных для предоставления конечным пользователям возможностей самостоятельной бизнес-аналитики.
Куб OLAP представляет собой структуру данных, которая обеспечивает возможность быстрого анализа данных за рамками ограничений реляционных баз данных. Кубы способны отображать и суммировать большие объемы данных, также предоставляя пользователям доступ к любым точкам данных с возможностью поиска. Таким образом, данные могут быть сведены, фрагментированы и обработаны по мере необходимости для решения самых широкого спектра вопросов, относящихся к интересующей вас области пользователя.
Поставщики программного обеспечения или разработчики информационных технологий, имеющие опыт работы с кубами OLAP, могут создавать пакеты управления для определения собственных расширяемых и настраиваемых кубов OLAP, основанных на инфраструктуре хранилища данных. Такие кубы хранятся в службах SQL Server Analysis Services (SSAS). Средства самостоятельной бизнес-аналитики, такие как Excel и SQL Server Reporting Services (SSRS), позволяют выбирать эти кубы в составе служб SSAS и использовать их для анализа данных с различных перспектив.
Для хранения всех своих транзакций и записей организации используют базы данных для обработки транзакций в реальном времени (OLTP). Как правило, записи в эти базы данных вносятся поочередно и содержат большой объем информации, которая может быть использована стратегами для принятия обоснованных решений в сфере бизнеса. Однако используемые для хранения данных базы данных плохо приспособлены для анализа. Поэтому извлечение ответов из этих баз данных требует много времени и усилий. Базы данных OLAP специально предназначены для упрощения извлечения необходимых сведений бизнес-аналитики из данных.
Кубы OLAP — это звено, завершающее облик решения по созданию и обслуживанию хранилищ данных. Куб OLAP, также известный как многомерный куб или «гиперкуб», представляет из себя структуру данных в составе служб SQL Server Analysis Services (SSAS), которая создается на основе баз данных OLAP и позволяет выполнять почти моментальный анализ данных. Топология данной системы показана на иллюстрации ниже.

Полезной функцией куба OLAP является то, что данные в кубе могут содержаться в статистическом («агрегатном») виде. Для пользователя это выглядит так, словно в кубе уже заранее есть все необходимые ответы, поскольку куб содержит множество предварительно вычисленных значений. Не отправляя запрос в исходную базу данных OLAP, куб может почти мгновенно возвращать ответы на широкий спектр вопросов.
Основной целью Service Manager кубов OLAP является предоставление поставщикам программного обеспечения или разработчикам информационных технологий возможности выполнять практически мгновенный анализ данных как для исторического анализа, так и для прогнозирования. Service Manager выполняет это следующим образом:
- Возможность встраивать определения кубов OLAP в пакеты управления. Такие кубы автоматически создаются в службах SSAS при развертывании пакета управления.
- Автоматическое обслуживание куба без вмешательства пользователей, включая ряд задач, в том числе выполнение обработки, секционирования, перевода и локализации, а также изменения схемы.
- Предоставление пользователям средств самостоятельной бизнес-аналитики, таких как Excel, для анализа данных с различных перспектив.
- Сохранение созданных отчетов Excel для дальнейшего использования.
Чтобы увидеть, как Кубы хранилища данных представлены в консоли Service Manager, перейдите в рабочую область хранилище данных и щелкните Кубы.
Service Manager Кубы OLAP
На рисунке ниже показано изображение из среды SQL Server Business Intelligence Development Studio (BIDS), на котором представлены основные части, необходимые для создания и работы кубов OLAP. Эти части — источник данных, представление источника данных, кубы и измерения. В приведенных ниже разделах описываются части куба OLAP и действия, которые могут выполнять пользователи с их помощью.
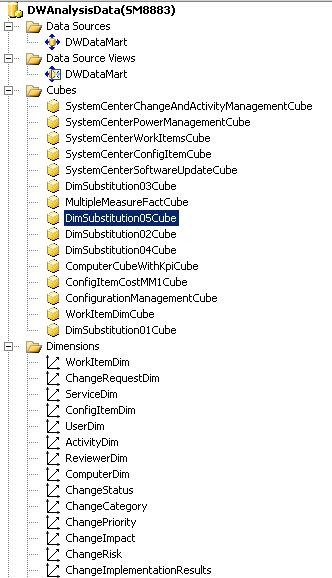
Источник данных
Источник данных является источником всех данных, содержащихся в кубе OLAP. Куб OLAP подключается к источнику данных для чтения и обработки необработанных данных путем выполнения агрегирования и вычислений связанных с ними мер. Источником данных для всех кубов Service Manager OLAP являются киоски данных, которые включают киоски данных как для Operations Manager, так и для Configuration Manager. Чтобы установить правильный уровень разрешений, сведения аутентификации для источника данных должны быть сохранены в службах SQL Server Analysis Services (SSAS).
Представление источника данных
Представление источника данных (DSV) представляет собой коллекцию представлений, которые представляют таблицы измерений, фактов и вспомогательное измерение из источника данных, такие как Service Manager киоски данных. DSV отображает все отношения между таблицами, в том числе первичные и внешние ключи. Другими словами, DSV показывает, как база данных SSAS будет сопоставлена с реляционной схемой, и предоставляет слой абстрагирования поверх реляционной базы данных. Данный слой абстрагирования позволяет определять отношения между таблицами фактов и измерений даже при отсутствии отношений в исходной реляционной базе данных. В DSV также можно определять именованные вычисления, пользовательские меры и новые атрибуты, отсутствующие в схеме измерений хранилища данных. Например, именованное вычисление, определяющее логическое значение для решаемых инцидентов , вычисляет значение true, если состояние инцидента — resolved или Closed. Используя именованное вычисление, Service Manager может определить меру для просмотра полезной информации, такой как процент разрешенных инцидентов, общее количество разрешенных инцидентов и общее число инцидентов, которые не разрешены.
Еще один краткий пример именованного вычисления — ReleasesImplementedOnSchedule. Это именованное вычисление выполняет быструю проверку состояния работоспособности, подсчитывая количество записей о выпусках, в которых фактическая дата реализации прежде или равна запланированной.
Кубы OLAP
Куб OLAP представляет собой структуру данных, которая обеспечивает возможность быстрого анализа данных, выходя за рамки ограничений реляционных баз данных. Кубы OLAP могут отображать и суммировать большие объемы данных, а также предоставлять пользователям доступ к любым точкам данных с возможностью поиска, чтобы эти данные можно было свести, разделить и обрезать по мере необходимости для обработки самых широкого спектра вопросов, относящихся к интересующей вас области пользователя.
Измерения
Измерение в службах SSAS ссылается на измерение из Service Manager хранилища данных. В Service Manager измерение примерно эквивалентно классу пакета управления. Каждый класс пакета управления имеет набор свойств, а каждое измерение — набор атрибутов, при этом каждый атрибут сопоставляется с одним свойством класса. Измерения позволяют выполнять фильтрацию, группирование и маркировку данных. К примеру, можно отфильтровать компьютеры по установленной операционной системе или сгруппировать людей по категориям, используя пол или возраст. Затем эти данные можно представить в формате, естественным образом разбивающем данные по выбранным иерархиям и категориям, тем самым позволяя выполнять их углубленный анализ. Измерения также могут иметь естественные иерархии, позволяющие пользователям «детализировать» до более детального уровня детализации. К примеру, измерение даты обладает иерархией, позволяющей выполнять детализацию до уровня лет, затем — до уровней кварталов, месяцев, недель и отдельных дней.
В следующем рисунке показан куб OLAP, содержащий измерения даты, региона и продукта.

например, членам группы Microsoft может потребоваться краткая и простая сводка продаж Xbox One игровой консоли в 2016. Они могут детализировать данную сводку для получения сведений о продажах за более узкий интервал времени. бизнес-аналитикам может потребоваться изучить, как повлияли продажи Xbox One консолей при запуске нового проектирования консоли и Kinect для Xbox One. Такая информация позволяет им выявить происходящие в сфере продаж тренды и разработать потенциальную корректировку бизнес-стратегии компании. Фильтрация по измерению даты позволяет быстро доставлять и использовать данную информацию. Описанное создание объемных и плоскостных срезов данных возможно благодаря наличию в измерениях атрибутов и данных, позволяющих клиенту с легкостью выполнять их фильтрацию и группирование.
В Service Manager все Кубы OLAP совместно используют общий набор измерений. Все измерения используют в качестве источника основной киоск данных хранилища данных, даже при наличии нескольких киосков данных. Таким образом, наличие нескольких киосков данных может привести к ошибкам ключей измерения при обработке куба.
Группа мер
Концепция группы мер совпадает с термином «факт» в контексте хранилища данных. Подобно тому, как факты содержат числовые меры в хранилище данных, группа мер содержит меры для куба OLAP. Все меры в кубе OLAP, происходящие от одной таблицы фактов в представлении источника данных, также могут считаться группой мер. Однако в определенных случаях меры в кубе OLAP могут происходить от нескольких таблиц фактов. Меры одинакового уровня детализации объединяются в одну группу мер. Группы мер определяют, какие данные будут загружены в систему, каким образом они будут загружены, а также как данные будут привязаны к многомерному кубу.
Каждая группа мер также содержит список разделов, в которых находятся сами данные в виде отдельных, неперекрывающихся блоков. Группы мер также обладают поддержкой агрегатов — готовых наборов данных, заранее вычисляемых для каждой группы мер с целью повышения производительности запросов пользователей.
Меры — это числовые значения, позволяющие пользователям создавать плоскостные и объемные срезы, выполнять агрегирование и анализ. Они являются одной из основных причин построения кубов OLAP на основании инфраструктуры хранилищ данных. При помощи служб SSAS можно создавать кубы OLAP, использующие бизнес-правила и вычисления для форматирования и отображения мер в настраиваемом формате. Большой объем времени разработки куба OLAP тратится на определение того, какие меры будут отображены, и каким образом они будут вычисляться.
Меры — это значения, обычно сопоставляемые с числовыми столбцами в таблице фактов хранилища данных, но их также можно создать из атрибутов измерения или вырожденного измерения. Эти меры являются самыми важными анализируемыми значениями куба OLAP и представляют основной интерес для пользователей, просматривающих куб OLAP. Пример меры, существующей в хранилище данных — ActivityTotalTimeMeasure. ActivityTotalTimeMeasure — это мера из факта ActivityStatusDurationFact, обозначающая время, которое каждое действие проводит в определенном состоянии. Уровень детализации меры состоит из всех охваченных ей измерений. К примеру, уровень детализации факта отношений ComputerHostsOperatingSystem состоит из измерений Computer и Operating System.
Функции агрегирования осуществляют вычисление на основе мер для возможности дальнейшего анализа данных. Наиболее распространенные функцией агрегирования является Sum («Сумма»). Один из распространенных запросов к кубу OLAP, к примеру, суммирует продолжительность всех действий, имеющих состояние In Progress. Другие распространенные функции агрегирования — Min, Max и Count.
После завершения обработки необработанных данных в кубе OLAP пользователи могут выполнять более сложные вычисления и запросы, используя многомерные выражения (MDX) для определения собственных выражений мер и их вычисляемых элементов. MDX — это отраслевой стандарт для операций запроса и доступа к данным, сохраненным в системах OLAP. SQL Server не предназначен для работы с моделью данных, которую поддерживают многомерные базы данных.
Детализация
Когда пользователь детализирует данные куба OLAP, он анализирует данные на другом уровне уплотнения. Уровень детальности данных повышается с каждой операцией детализации, что позволяет пользователю изучать данные на разных уровнях иерархии. По мере детализации пользователь переходит от общей информации к данным, имеющим более узкий фокус. Ниже приведены примеры детализации.
- Детализация данных для просмотра демографической информации о населении США, затем штата Вашингтон, затем — муниципального района Сиэтл, города Редмонд и, в заключение, штаб-квартиры Майкрософт.
- детализируйте показатели продаж для консолей Xbox One для 2015 календарного года, затем четвертого квартала года, месяца декабря, недели до рождества и, наконец, рождества.
Детализация
Когда пользователи детализируют данные, они хотят видеть все отдельные транзакции, которые были задействованы в статистических данных куба OLAP. Другими словами, пользователь может извлечь данные на самом низком уровне детализации для определенного значения меры. Например, имеются категория продуктов и данные продаж за определенный месяц. Вы можете выполнить детализацию этих данных в режиме «drill through», чтобы увидеть список всех строк таблицы, содержащихся в данной ячейке данных.
Часто термины «Детализация» и «Детализация» следует путать друг с другом. Основное различие между ними заключается в том, что Детализация работает с предопределенной иерархией данных, например США, затем в Вашингтон, затем в Сиэтле — в кубе OLAP. Детализация «drill-through» позволяет перейти на самый низший уровень детализации и извлечь из источника данных набор строк, составляющих одну ячейку агрегата.
Ключевой показатель эффективности
Организации могут использовать ключевые показатели эффективности для отслеживания продвижения своего предприятия в сторону заданных целей, таким образом измеряя его работоспособность и производительность. Показатели KPI представляют из себя бизнес-метрики, создаваемые для наблюдения за продвижением в сторону определенных заданных целей. Как правило, у показателя KPI имеется фактическое значение и целевое значение, представляющее собой количественную цель, достижение которой важно для успеха организации. Показатели KPI обычно отображаются в виде групп в системе показателей, демонстрируя общую работоспособность бизнеса в виде одного моментального снимка.
Пример показателя KPI: выполнить все запросы на изменение в течение 48 часов. Показатель KPI можно использовать для определения процентной доли выполненных в течение этого интервала времени запросов на изменение. Для визуального представления показателей KPI предусмотрена возможность создания панелей мониторинга. Например, можно определить целевое значение KPI как «выполнить все запросы на изменение в течение 48 часов на 75 процентов».
Разделы
Раздел — это структура данных, содержащая частичные или полные данные группы мер. Все группы мер поделены на разделы. Раздел определяет подмножество данных факта, загруженное в группу мер. SSAS Standard Edition поддерживают только один раздел на группу мер, а в SSAS Enterprise Edition поддерживаются несколько разделов. Секции прозрачны для конечного пользователя, но они оказывают сильное влияние на производительность и масштабируемость кубов OLAP. Все разделы группы мер всегда существуют в одной и той же физической базе данных.
Секции позволяют администратору лучше управлять кубом OLAP и повысить производительность куба OLAP. Например, можно удалить или повторно обработать данные в одной секции группы мер, не затрагивая остальную часть группы мер. При загрузке новых данных в таблицу фактов затрагиваются только секции, которые должны содержать новые данные.
Секционирование также повышает производительность обработки и запросов для кубов OLAP. Службы SSAS могут параллельно обрабатывать несколько секций, в результате чего ресурсы ЦП и памяти на сервере используются гораздо более эффективно. При выполнении запроса службы SSAS также извлекают, обрабатывают и агрегируют данные из нескольких секций. Сканируются только секции, которые содержат данные, относящиеся к запросу, в результате чего снижается общий объем входных и выходных данных.
Одним из примеров стратегии секционирования служит размещение данных фактов для каждого месяца в месячной секции. В конце каждого месяца все новые данные переносятся в новую секцию, в результате чего выполняется естественное распределение данных с неперекрывающимися значениями.
Агрегации
Агрегаты в кубе OLAP — это предварительно просуммированные наборы данных. Они аналогичны инструкции SQL SELECT с предложением GROUP BY. Службы SSAS могут использовать эти агрегаты при ответе на запросы, чтобы сократить количество необходимых вычислений и быстро возвращать ответы пользователю. Агрегаты, встроенные в куб OLAP, сокращают количество операций агрегирования, выполняемых службами SSAS во время запроса. Построение правильных агрегатов может существенно улучшить производительность запросов. Зачастую это процесс, развивающийся в течение времени существования куба OLAP по мере изменения его запросов и использования.
Обычно создается базовый набор агрегатов, которые будут использоваться для большинства запросов к кубу OLAP. Агрегаты строятся для каждой секции куба OLAP в пределах группы мер. Когда агрегат построен, некоторые атрибуты измерений добавляются в предварительно просуммированный набор данных. При просмотре кубов OLAP пользователи могут быстро запрашивать данные на базе этих агрегатов. К разработке агрегатов следует подходить со всей тщательностью, поскольку количество потенциальных агрегатов столь велико, что для построения всех из них может потребоваться слишком много времени и дискового пространства.
При построении и проектировании агрегатов в Service Manager кубах OLAP Service Manager использует следующие два параметра:
- Рост производительности достиг
- Оптимизация с учетом использования
Параметр «Рост производительности достиг» определяет процент создаваемых агрегатов. Например, если для этого параметра установить используемое по умолчанию рекомендуемое значение в 30 процентов, построение агрегатов будет продолжаться до тех пор, пока предполагаемый рост производительности куба OLAP не составит 30 процентов. Однако это не означает, что будет построено 30 процентов возможных агрегатов.
Оптимизация с учетом использования позволяет службам SSAS вести журнал запросов данных, чтобы при выполнении запроса сведения передавались в процесс разработки агрегатов. Затем службы SSAS проверяют данные и рекомендуют агрегаты для построения с целью достижения наибольшего предполагаемого роста производительности.
Секционирование Куба Service Manager
Все группы мер в кубе поделены на разделы, каждый из которых определяет часть данных факта, загружаемую в группу мер. SQL Server Analysis Services (SSAS) в SQL Server Standard Edition допускает только один раздел на группу мер, в то время как в выпуск Enterprise разрешено несколько секций. Разделы полностью прозрачны для пользователя, однако они имеют большое влияние на производительность и масштабируемость. Например, разделы могут быть обработаны по отдельности и параллельно. Они могут иметь различные статистические схемы. Можно выполнить повторную обработку раздела, не затрагивая другие разделы группы мер. Кроме того, система SSAS автоматически сканирует только те разделы, которые содержат необходимые для запроса данные, что позволяет значительно повысить производительность запросов.
Секционирование кубов выполняется при каждом запуске задания по обслуживанию хранилища данных — по умолчанию ежечасно. Выполняемый модуль данного процесса называется ManageCubePartitions. Его выполнение происходит всегда после этапа CreateMartPartitions. Данные зависимостей хранятся в таблице infra.moduletriggercondition.
Главная библиотека DLL, ответственная на секционирование, находится в служебной библиотеке DLL хранилища, Microsoft.EnterpriseManagement.Warehouse.Utility, в классе PartitionUtil. Конкретно же все задачи обслуживания разделов осуществляются при помощи метода ManagePartitions() в данном классе. Используемые для обслуживания и оперативной аналитической обработки хранилища данных библиотеки DLL Microsoft.EnterpriseManagement.Warehouse.Maintenance и Microsoft.EnterpriseManagement.Warehouse.Olap, вызывают библиотеку Microsoft.EnterpriseManagement.Warehouse.Utility для обработки разделов во время обслуживания хранилища и развертывания куба. Таким образом фактическое управление разделами осуществляется в общей служебной библиотеке DLL во избежание дублирования логики и кода.
Функция обслуживания секционирования куба выполняет следующие задачи:
- Создание секций
- Удаление разделов
- Обновление границ разделов
При выполнении этих задач осуществляется чтение таблицы SQL etl.TablePartition с целью определить все разделы фактов, созданные для данной группы мер. После этого будут выполнены указанные ниже действия:
- Запуск обработки куба для каждой группы мер в кубе
- Получение всех разделов из таблицы etl.TablePartition для группы мер
- Удаление всех разделов, имеющихся в группе мер, но отсутствующих в таблице etl.TablePartition
- Добавление всех новых разделов, существующих только в таблице etl.TablePartition
- Обновление разделов, которые могли измениться, путем сопоставления каждого раздела с параметрами RangeStartDate и RangeEndDate в таблице etl.TablePartition
Помните о следующих нюансах обработки куба:
- только группы мер, нацеленные на факты, содержат несколько секций в SQL Server Standard выпуске. По умолчанию все группы мер и измерения содержат только один раздел. Поэтому у раздела отсутствуют какие-либо условия границы.
- Границы раздела определяются с помощью привязки запроса, основанной на ключах дат, совпадающих с ключами дат соответствующего раздела факта в таблице etl.TablePartition.
Развертывание куба OLAP Service Manager
развертывание куба olap использует инфраструктуру развертывания Service Manager для создания кубов olap в базе данных SQL Server Analysis Services (SSAS).
Развертываемый элемент возвращает развертывающий объект с коллекцией ресурсов, которые сериализуются и используются для создания куба OLAP в базе данных SSAS. В кубах OLAP развертываемый объект называется CubeDeployable (для элемента SystemCenterCubе) или CubeExtensionDeployable (для элемента CubeExtension). Развертывающим объектом для обоих элементов является CubeDeployer.
Таблица dbo.Selector в базе данных DWStagingAndConfig содержит данные по обоим элементам пакета управления (SystemCenterCube и CubeExtension). Подсистема развертывания использует эти метаданные в том случае, если при импорте пакета управления в хранилище данных с применением задания MPSync требуется дополнительная обработка элемента пакета управления.
В ходе развертывания для создания и модификации всех компонентов куба в базе данных SSAS используется программный интерфейс объектов AMO. А именно, используются объекты AMO в разъединенном режиме, поскольку элемент CubeDeployable не будет обладать подключением к базе данных SSAS. Работа с объектами AMO в разъединенном режиме позволяет создавать полное дерево объектов AMO без подключения к серверу. Service Manager затем сериализует иерархию объектов в виде потоковых ресурсов и присоединяет их к объекту-источнику развертывания, который передается обратно в инфраструктуру развертывания. Затем выполняется десериализация развертывающего объекта, устанавливается подключение к базе данных SSAD и создаются объекты с помощью отправки соответствующих запросов в базу данных.
Возможна сериализация только главных объектов. В контексте объектов AMO главными объектами считаются классы, которые представляют собой завершенный объект в виде завершенной сущности, не являющийся частью другого объекта. Примерами главных объектов являются Server, Cube и Dimension, каждый из которых является изолированной сущностью. Однако DimensionAttribute не является главным объектом, поскольку он может быть создан только в составе родительского главного объекта Dimension. DimensionAttribute, таким образом, является дополнительным объектом. Проектировочный этап куба OLAP сфокусирован на создании всех главных объектов, необходимых кубу, вместе с их зависимыми дополнительным объектами. Эти основные объекты являются объектами, которые будут сериализованы, и, в конечном итоге, десериализованы, перед созданием объектов в базе данных SSAS.
Для успешного завершения развертывания и удовлетворения зависимостей, предъявляемых элементами куба OLAP, ресурсы, обертывающие главные объекты, должны быть созданы в определенном порядке. В двух представленных ниже списках показана последовательность развертывания элементов SystemCenterCube и CubeExtension, соответственно.
- элементы DataSourceView
- элементы измерения
- элемент измерения даты
- элемент куба
- элементы DataSourceView
- элемент куба
Обработка Service Manager куба OLAP
После развертывания куба OLAP и создания всех его разделов куб готов к обработке, которая сделает его просматриваемым. Обработка куба — финальный шаг перед запуском процессов извлечения, преобразования и загрузки (ETL). Эти действия происходят в следующем порядке:
- Извлечение: извлечение данных из исходной системы.
- Преобразование: применение функций для приведения данных в соответствие со стандартной схемой измерений.
- Загрузка: загрузка данных в киоск данных для потребления.
- Процесс: загрузка данных из киоска данных в куб OLAP для просмотра.
Обработка куба OLAP начинается после того, как выполнено вычисление всех агрегатов куба и куб загружен вместе с этими агрегатами и данными. Выполняется чтение таблиц фактов и измерений, а также вычисление данных и их загрузка в куб. При проектировании куба OLAP следует учитывать потенциально сильное влияние, которое процесс обработки способен оказать на рабочую среду, где могут существовать миллионы записей. Полная обработка всех секций в такой среде может занять от нескольких дней до нескольких недель, что может привести к отображению Service Manager инфраструктуры и кубов, непригодных для конечных пользователей. Рекомендуется отключить график обработки неиспользуемых кубов, чтобы снизить нагрузку на систему.
Обработка куба OLAP состоит из двух отдельных задач:
- Обработка измерений.
- Обработка разделов.
Каждый куб OLAP имеет соответствующее задание обработки в консоли Service Manager и выполняется по расписанию, настраиваемому пользователем. Эти задания описаны в разделах, приведенных ниже.
Обработка измерений.
Каждое добавляемое в базу данных SSAS измерение должно подвергнуться полной обработке, чтобы получить состояние «обработано». При обработке другого куба, ссылающегося на уже обработанное измерение, повторная обработка данного измерения может быть автоматически пропущена. Если не выполнить автоматическую повторную обработку измерения, Service Manager повторно обрабатывать каждое измерение для каждого куба. Наибольший эффект достигается с недавно обработанными измерениями, где маловероятно наличие новых, еще необработанных данных. Для оптимизации эффективности обработки предусмотрен Singleton-класс Microsoft.SystemCenter.Warehouse.Dimension.ProcessingInterval, определенный в пакете управления Microsoft.SystemCenter.Datawarehouse.OLAP.Base. Образец данного класса приведен ниже.
Данный Singleton-класс содержит свойство IntervalInMinutes, определяющее частоту обработки измерения. По умолчанию это свойство имеет значение 60 минут. К примеру, если измерение было обработано в 15:05, а другой куб, ссылающийся на это же измерение, был обработан в 15:45, измерение не будет обработано повторно. Недостатком данного подхода является повышение вероятности ошибок в ключах измерения. Механизм повторной попытки обрабатывает ошибки ключей измерения, чтобы выполнить повторную обработку измерения с последующей обработкой раздела куба. Дополнительные сведения об ошибках обработки см. в разделе «распространенные проблемы с отладкой и устранением неполадок».
После полной обработки измерения выполняется добавочная обработка с помощью операции ProcessUpdate . Операция ProcessFull выполняется лишь в еще одном случае — при изменении схемы измерения, поскольку это действие приводит к возврату измерения в необработанное состояние. Помните, что выполнение операции ProcessFull на измерении приведет все затронутые кубы и их разделы в необработанное состояние, что повлечет за собой их полную обработку при следующем запланированном запуске.
Обработка разделов.
Обработка разделов требует тщательного планирования, поскольку повторная обработка крупного раздела является крайне медленным процессом, потребляющим большой объем ресурсов ЦП на сервере, где размещены службы SSAS. Как правило, обработка разделов занимает больше времени, чем обработка измерений. В отличие от обработки измерений, обработка разделов не имеет влияния на другие объекты. только два типа обработки, выполняемые в System Center 2016-Service Manager кубы OLAP, — это ProcessFull и ProcessAdd.
Подобно измерениям, создание новых разделов в кубе OLAP требует, чтобы относящаяся к разделу задача ProcessFull находилась в состоянии, реагирующем на запросы. Поскольку задача ProcesFull — ресурсоемкая операция, ее следует выполнять только при необходимости, например, при создании раздела или при обновлении строки. В сценариях, в которых строки были добавлены и ни одна из строк не обновлялась, Service Manager может выполнить задачу ProcessAdd. Для этого Service Manager использует водяные знаки и другие метаданные. При этом опрашиваются таблицы etl.cubepartition и etl.tablepartition для определения режима необходимой обработки.
На следующей схеме показано, как Service Manager определяет тип выполняемой обработки на основе данных водяного знака.
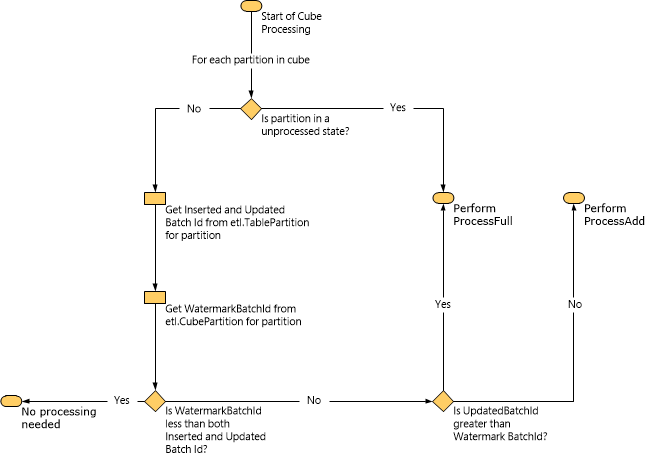
При выполнении задачи ProcessAdd Service Manager ограничивает область запроса с помощью водяных знаков. Например, если значение InsertedBatchId равно 100, а значение WatermarkBatchId — 50, запрос загружает данные только из того киоска данных, где InsertedBatchId имеет значение больше 50 и меньше 100.
И, наконец, важно отметить, что Service Manager не поддерживает ручную обработку кубов OLAP с помощью SSAS или Business Intelligence Development Studio. обработка кубов за пределами методов, предоставляемых System Center-Service Manager, включая консоль Service Manager и командлеты Service Manager, не приведет к обновлению таблиц водяных знаков. Из-за этого существует вероятность нарушения целостности данных. Если вы случайно вручную выполнили повторную обработку куба, возможным решением является так же вручную обратить процесс. Затем при следующем Service Manager обрабатывается куб, он автоматически выполняет задачу ProcessFull, так как секции будут находиться в необработанном состоянии. Это приведет к корректному обновлению всех водяных знаков и метаданных, что позволит устранить все возможные проблемы целостности данных.
Ведение кубов Service Manager OLAP
В представленных ниже разделах даются рекомендации по обслуживанию кубов OLAP.
Периодическая повторная обработка Analysis Services измерений
При работе со службами SQL Server Analysis Services рекомендуется регулярно выполнять полную обработку измерений SSAS. При полной обработке измерений происходит перестройка индексов и оптимизация хранения многомерных данных, что повышает производительность запросов (а также производительность куба), которая может снижаться с течением времени. Это процесс подобен регулярной дефрагментации жесткого диска на компьютере.
Негативным последствием полной обработки измерения SSAS является то, что все соответствующие кубы OLAP становятся необработанными и должны тоже быть полностью обработаны для возврата в состояние, позволяющее им отвечать на запросы. Service Manager явно не полностью обрабатывает измерения SSAS. Время выполнения этой задачи обслуживания необходимо выбрать самостоятельно.
Требования к памяти
Если все операции хранилища данных по извлечению, преобразованию и загрузке (ETL), а также функции куба OLAP выполняются на одном сервере, будьте внимательны при подсчете памяти, необходимой для работы операционной системы, хранилища данных и служб SSAS. Убедитесь, что сервер способен обеспечить одновременное выполнение множества операций обработки данных. Этот момент особенно важен, поскольку операция обработки кубов OLAP требовательна к памяти.